修复抓取错误并提升网站抓取能力
专家评审

抓取访问问题是限制SEO增长的最快方式之一:页面可能存在,但搜索引擎无法持续地发现、获取、渲染和索引它们。对于营销和运营团队来说,这通常表现为索引缓慢、搜索结果中缺少分类或地区页面,以及永远无法转化为咨询的内容。
本操作指南将带您了解一个实用且优先级的诊断和修复抓取问题工作流程,包括robots.txt问题、抓取错误和被阻止的资源,而不会试图一次解决所有问题。
1) 绘制抓取流程图(以便修复正确的层级)
在更改文件或重定向规则之前,请与您的团队就故障发生的位置达成一致。现代搜索引擎通常遵循以下顺序:发现URL、检查robots规则、获取HTML、渲染(通常执行JavaScript),然后决定是否索引。

使用此心智模型来避免常见错误,例如将索引问题视为抓取问题(或在robots.txt中阻止您实际想要取消索引的页面)。
如果您需要官方定义来统一利益相关者,Google的抓取和索引概述是最清晰的参考:Google crawling and indexing documentation。
2) 使用Google Search Console快速诊断(首先要看什么)
Google Search Console是关于Google无法获取的内容、排除的内容以及减速位置的最快真实来源。
高信号分类清单:
- 页面报告:像"服务器错误(5xx)"、"未找到(404)"、"软404"、"重定向错误"和"被robots.txt阻止"等集群。
- 抓取统计:响应时间峰值、5xx百分比上升或抓取请求急剧下降。
- URL检查:确认特定URL是否被阻止、可获取和可渲染。
有用的参考:
- Robots基础和测试:Google robots.txt introduction
- 抓取预算概念(特别是对于大型目录):Google crawl budget explanation
- 抓取错误背景(较旧但仍有用的概念):Google crawl errors overview
繁忙团队的实际技巧:导出受影响的URL并按模板分组(产品、分类、博客、语言文件夹)。修复一个模板错误通常可以解决数千个URL。
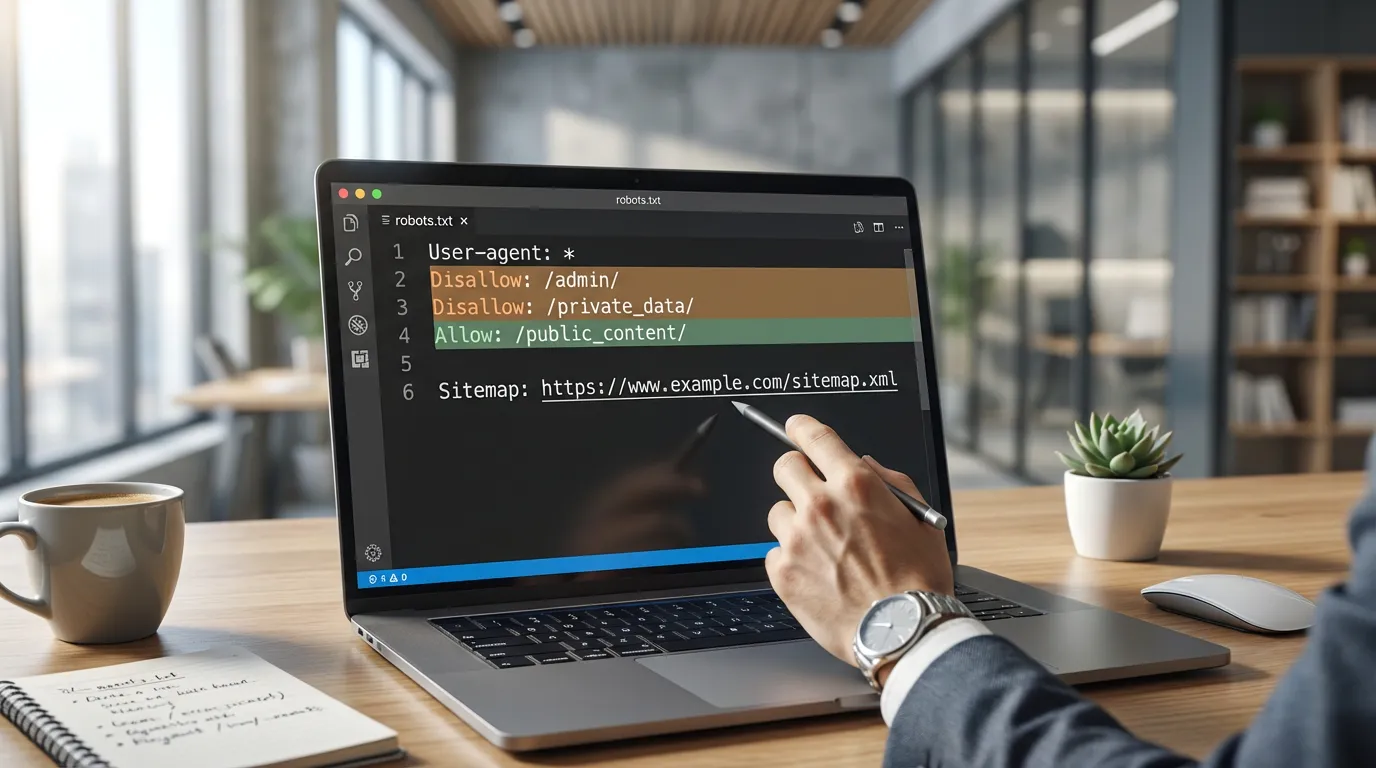
3) 修复robots规则而不意外隐藏收入页面
Robots规则很强大,但它们也是意外可见性损失的常见来源。重点关注两个结果:(1)重要部分可被抓取,(2)低价值部分不会浪费抓取。
要检查的常见robots错误配置
- 整个网站被阻止(例如,全局禁止规则)。
- 重要文件夹被阻止(博客、产品、分类或区域/语言目录)。
- 渲染资源被阻止(CSS或JS目录),这可能阻止正确的渲染。
- 使用robots规则作为取消索引方法,这通常会适得其反,因为阻止会阻止爬虫看到页面级别的noindex指令。
Google指出,robots规则控制抓取,而不是保证从索引中移除。对于您想从搜索中排除的页面,请改用页面上的noindex(或通过标头):Google关于使用noindex阻止索引的指导。
允许与阻止的内容(简单默认值)
| 区域 | 通常允许抓取 | 通常限制 | 为什么重要 |
|---|---|---|---|
| 核心页面 | 首页、分类、产品、核心服务页面、主要地区页面 | 无 | 这些页面推动排名和咨询。 |
| 渲染所需的资源 | CSS、关键JS包、用于主要内容的图片 | 非必要的跟踪脚本(如果它们不是渲染必需的) | 阻止必要的资源可能破坏渲染并降低索引质量。 |
| 低价值页面 | 无 | 内部搜索、购物车、结账、账户、管理 | 防止在非搜索页面上浪费抓取容量。 |
| 参数化URL | 规范页面 | 某些过滤器和跟踪参数的无限组合 | 有助于减少重复抓取和索引膨胀。 |
如果您需要常见robots陷阱的实用清单,请参见:Search Engine Journal's robots issue guide。
4) 按优先级顺序解决抓取错误和被阻止的资源
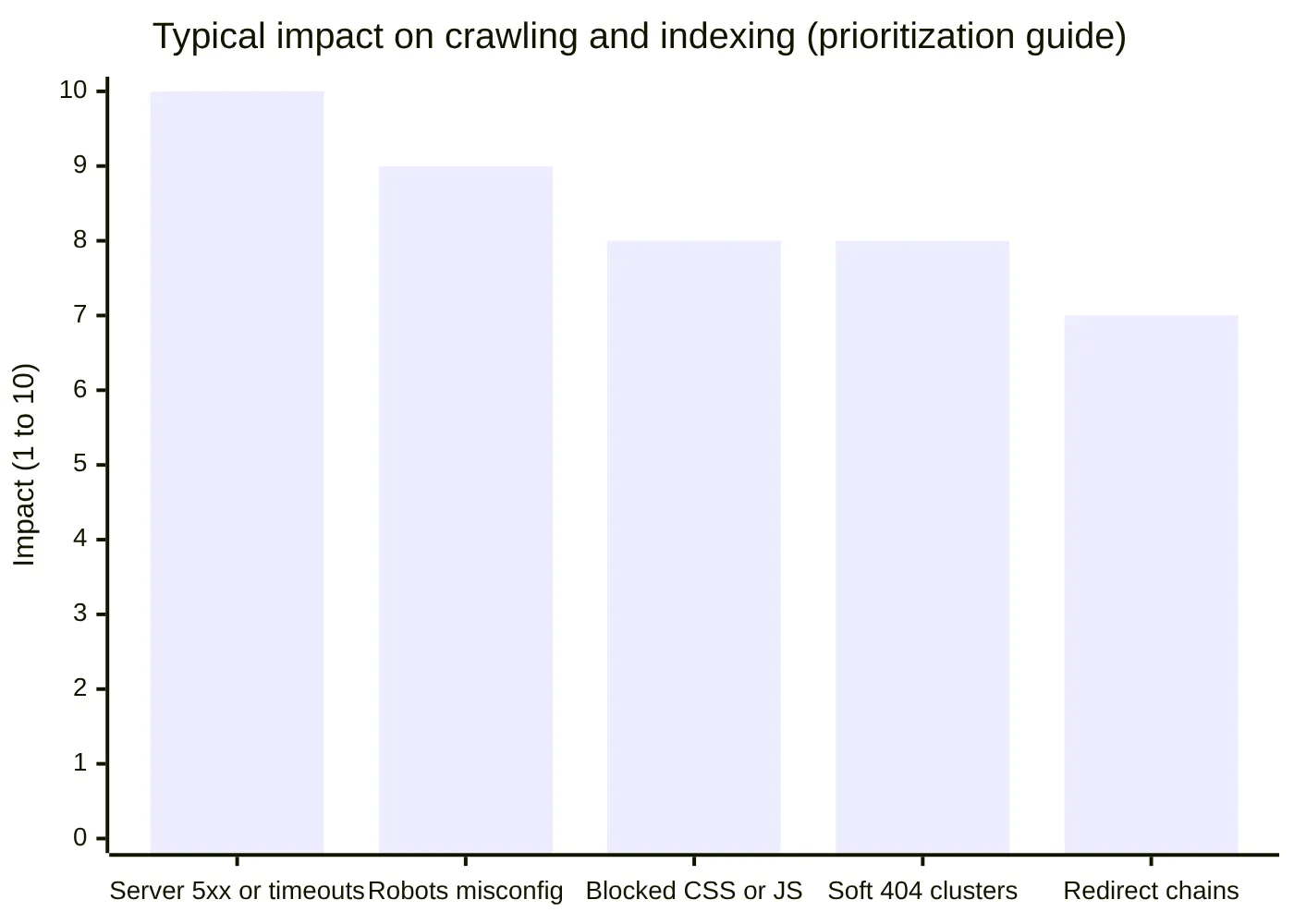
并非所有错误都同样紧急。某些高影响模式可以抑制整个网站的抓取,尤其是在大型目录或多区域构建上。
通常能带来最大收益的优先级顺序
- 服务器不稳定(DNS、重复的5xx、超时):当网站不可靠时,Google会减少抓取活动。
- 意外阻止:关键模板上的robots规则或身份验证阻止。
- 关键渲染失败:必要的CSS/JS被阻止,导致渲染不完整。
- 重定向链和循环:浪费抓取并削弱内部信号。
- 大规模软404模式:返回200 OK的薄弱或空页面。
要验证资源是否被阻止,请使用明确标记被阻止资源的爬虫报告。Screaming Frog记录了"外部阻止资源"的含义及其检测方式:Screaming Frog blocked resource explanation。
实用的修复和验证循环
- 在Search Console中确认问题集群(页面报告或URL检查)。
- 使用全站抓取重现它(这样您可以看到按模板的模式)。
- 应用最小的安全更改(例如,取消阻止一个目录、修复一个重定向规则、修复一个共享组件)。
- 在URL检查中重新测试一组URL样本,然后监控抓取统计以改进。
5) 通过架构、内部链接和国际设置改善抓取效率
一旦紧急阻止被移除,下一个收益通常来自于使重要页面更容易被发现和重新抓取。
架构和内部链接(要改变什么)
- 将关键页面保持在距枢纽页面大约三次点击的范围内,不要埋入深层导航中。
- 通过确保每个重要URL至少从一个相关枢纽链接并包含在干净的站点地图中,来减少孤立页面。
- 使用描述性的内部锚文本,使网站的主题结构对爬虫清晰。
站点地图、规范和hreflang(国际网站)
面向出口的网站经常遇到困难,因为语言和区域版本会随时间漂移。三条规则可以防止许多问题:
- 站点地图只应列出规范的、可索引的URL:Google sitemap management
- 规范必须不指向被阻止或noindex的URL(这可能静默破坏索引信号)。
- Hreflang目标必须可抓取和可索引,否则国际定位会崩溃:Google hreflang guide
当涉及JavaScript时
如果关键内容或链接仅在客户端渲染后出现,索引可能会延迟。考虑对优先级模板进行服务器端渲染或预渲染,并确保必要的JS资源可访问。关于Google如何处理JavaScript的清晰解释,请参见:Vercel's breakdown of Google and JavaScript indexing。
下一步(将修复转化为可衡量的SEO进展)
一个对抓取友好的网站不是最终目标。它是让您的最佳页面快速被发现、正确索引并在美国、欧洲和亚太地区可靠更新的基础。
如果您想要一个清晰的行动计划(而不是一长串低优先级问题),SeekLab.io通常分阶段进行:
- 首先稳定并解除关键部分的阻止。
- 然后改进结构、内部链接和站点地图卫生。
- 然后优化渲染、性能和国际一致性。


