How to Get Your Web3 Project Cited by ChatGPT and Perplexity in 2026
Expert reviewed

A Web3 project gets closer to ChatGPT and Perplexity citations by making its official website crawlable, verifiable, structured, current, and useful enough to serve as the primary source for its protocol, token, documentation, ecosystem, and use cases.
ChatGPT Search can show links to relevant web sources, and OpenAI states that ChatGPT Search may display inline citations or a Sources panel. Perplexity states that its answers include clickable citations for verification. No public source provides a fixed formula for earning those citations. The operational target for web3 SEO is readiness: make each important page easy to access, parse, summarize, verify, and connect to a clear next step.
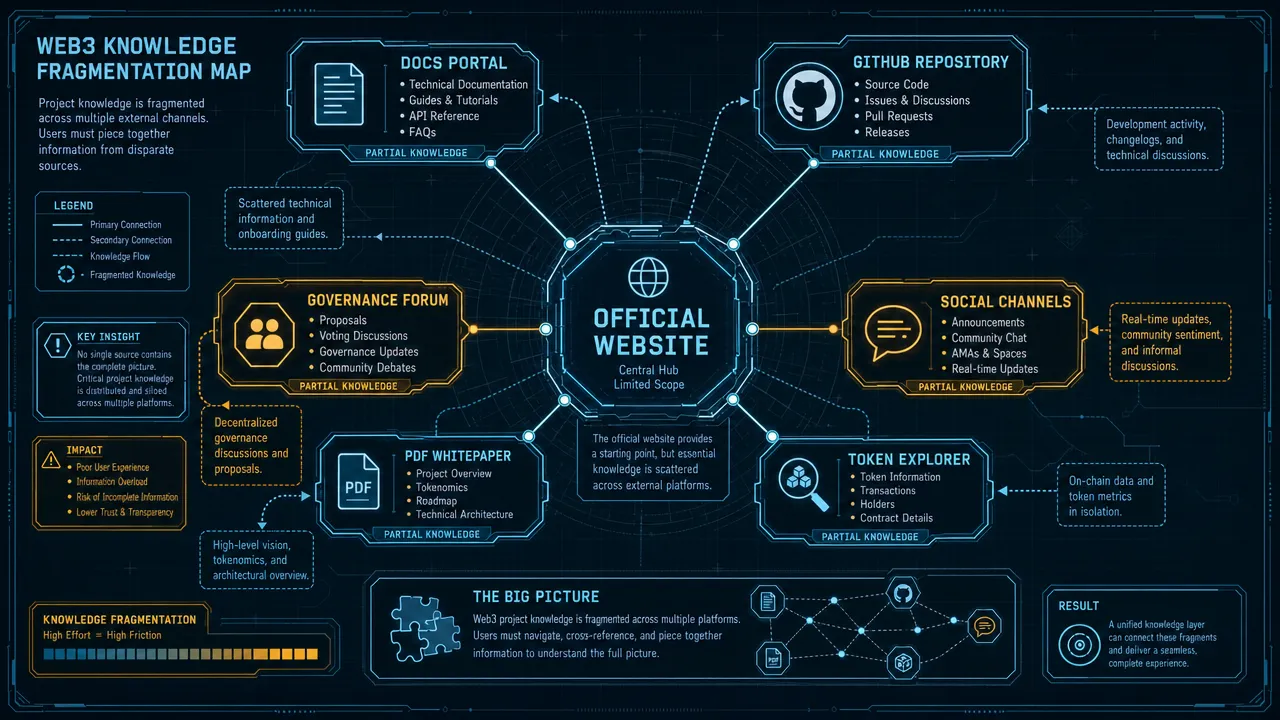
For Web3 teams, the main blocker is usually not a missing keyword list. The blocker is scattered knowledge. Token details may live in a PDF, integration notes in GitHub, roadmap updates on X, decisions in a governance forum, and tutorials in docs. AI answer engines and search engines need stable, official pages. Treat the website as the canonical reference layer before adding more content.
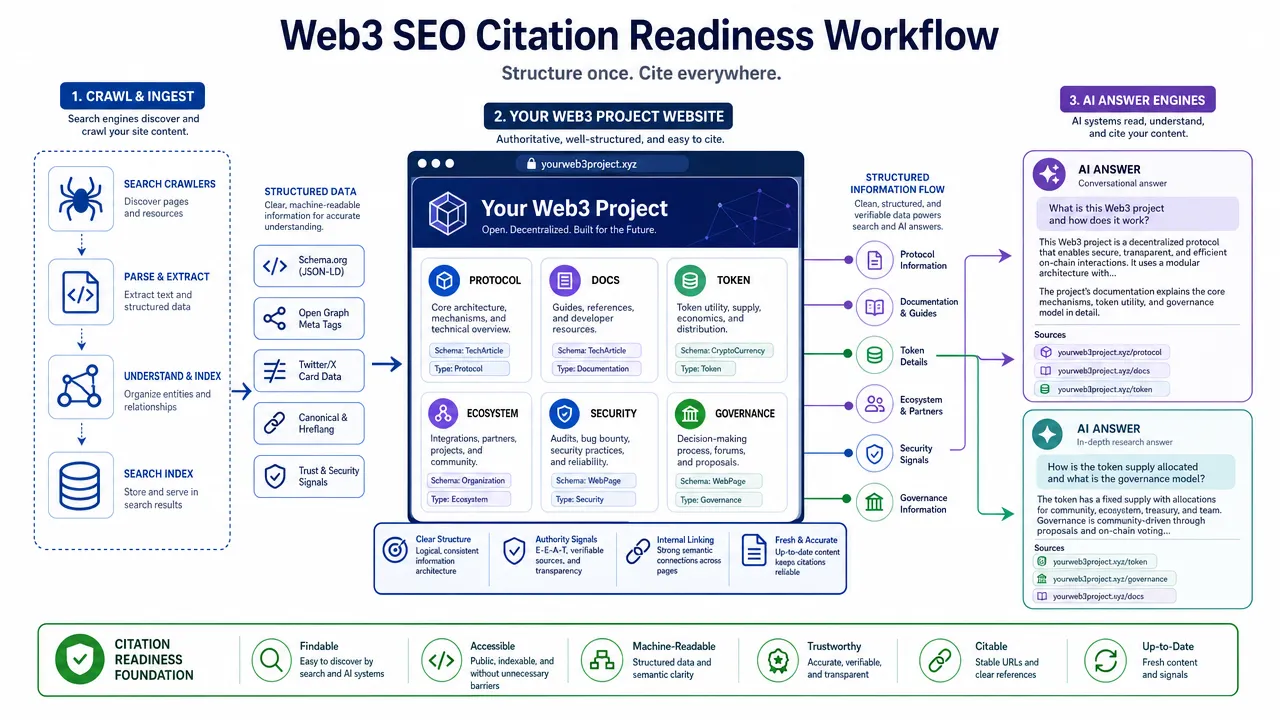
How Web3 SEO makes an official project website citation-ready
Web3 SEO is the process of making a protocol, product, chain, token, documentation hub, and ecosystem discoverable through traditional search and retrievable by AI answer engines. It includes technical SEO, entity clarity, documentation structure, content depth, structured data, multilingual architecture, internal links, and conversion paths.
Do not treat web3 SEO as keyword placement for crypto terms. A Web3 project has more entity risk than a normal SaaS website. Search systems must understand what the project is, which pages are official, what the token or protocol does, how developers use it, and which claims are current.
Use this rule:
| Requirement | Operational meaning | Common Web3 failure |
|---|---|---|
| Crawlable | Bots can reach key pages without blocked resources or authentication barriers. | Docs or app routes are hidden behind JavaScript or blocked folders. |
| Indexable | Canonical pages are not noindexed, duplicated, or redirected incorrectly. | Token, docs, or ecosystem pages compete with copies on subdomains. |
| Extractable | Main facts appear in clear HTML sections with headings, summaries, tables, and internal links. | Important details are locked in PDFs, images, Discord threads, or vague landing pages. |
| Verifiable | Claims are backed by official docs, security pages, governance records, partner pages, or authoritative references. | Social posts make claims that never appear on the official website. |
| Current | Pages show update dates, changelogs, version notes, or release status where needed. | Roadmap, token, API, and security information becomes stale. |
| Actionable | Each page gives the right next step for developers, users, partners, or community members. | Traffic lands on content but finds no docs link, signup, contact path, or integration step. |
Citation-ready does not mean guaranteed citation. It means the page is a strong candidate because it is accessible, specific, current, and trustworthy.
Use official documentation as the baseline. Google states in its AI optimization guidance that AI-era discoverability remains rooted in SEO fundamentals. Google's SEO Starter Guide also emphasizes discoverable, useful, and accessible content.
For a Web3 project, build these official pages first:
| Official page | Required content | Practical purpose |
|---|---|---|
| Protocol overview | Definition, supported chains, architecture summary, use cases, docs links. | Gives AI systems and users one canonical explanation. |
| Token page | Utility, contract references, governance role, risk notes, update date. | Reduces confusion from third-party token pages. |
| Security page | Audit links, bug bounty information, incident notes if applicable, disclosure policy. | Supports trust-sensitive queries. |
| Governance page | Proposal process, voting links, forum links, treasury references if applicable. | Clarifies decision-making. |
| Docs home | API, SDK, tutorials, versioning, changelog, troubleshooting. | Converts search traffic into developer adoption. |
| Ecosystem page | Integrations, partners, apps, wallets, developer links, proof references. | Prevents logo-only pages with weak search value. |
| Glossary and FAQ | Short definitions, examples, internal links, source-backed answers. | Matches conversational search and AI answer formats. |
A one-page launch site is not enough. It may look complete to a community member who already knows the project, but it gives crawlers and AI answer engines too little URL-level context.
How ChatGPT and Perplexity handle sources in web3 SEO planning
ChatGPT and Perplexity should be planned for as search-backed answer systems, not as platforms that can be forced to cite a page. OpenAI says ChatGPT Search can provide timely answers with links to relevant web sources. OpenAI's Help Center explains that ChatGPT Search can show inline citations or a Sources panel. Perplexity states that answers include clickable citations.
The safe working model is simple:
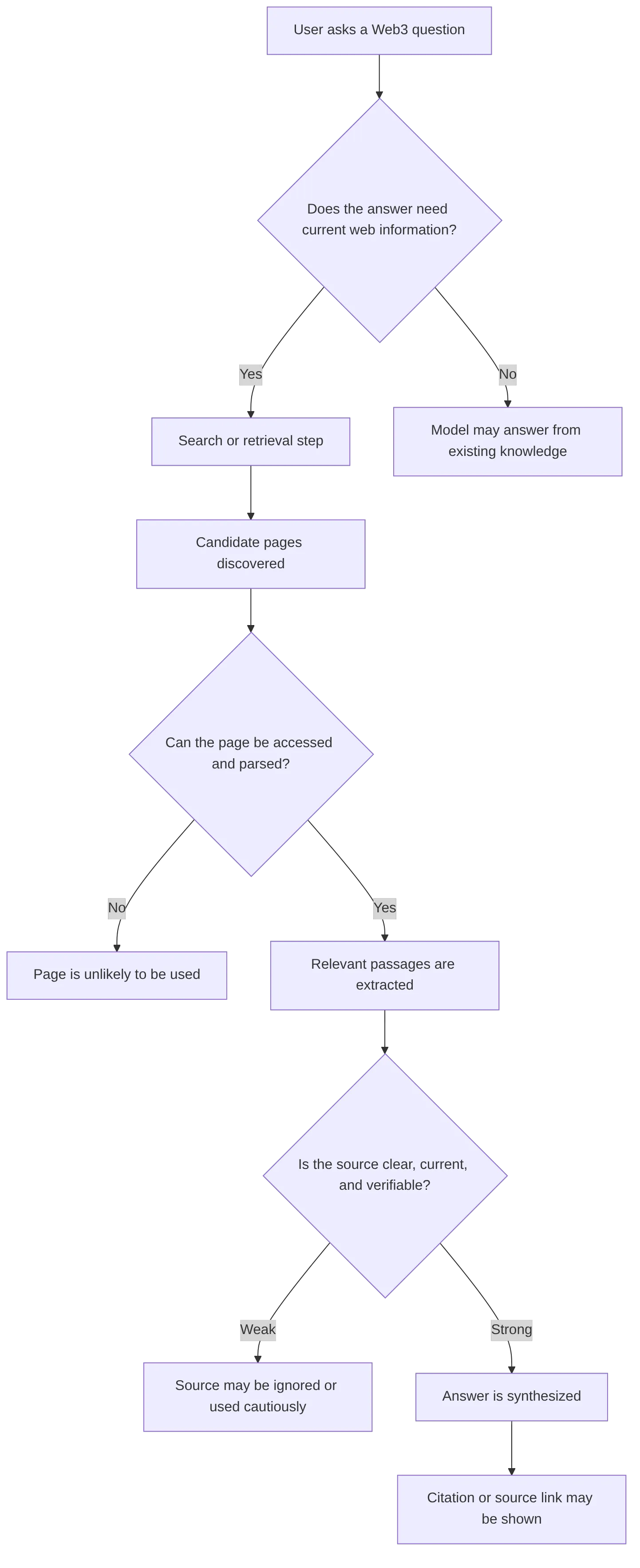
Treat this as a planning model, not a disclosed ranking formula. It reflects official statements about search-backed answers and normal retrieval behavior.
Use this distinction when setting web3 SEO priorities:
| Area | Traditional search requirement | Citation-readiness requirement |
|---|---|---|
| Page access | Crawl and index the page. | Retrieve, parse, and extract the relevant answer. |
| Content format | Satisfy search intent across a page. | Provide concise answer blocks, definitions, tables, and source-backed passages. |
| Authority | Earn trust through relevance, links, brand, and helpful content. | Show official status, corroboration, freshness, and low ambiguity. |
| User path | Get the click from search results. | Earn the citation, then convert the user after the click. |
| Measurement | Rankings, impressions, clicks, conversions. | AI referral traffic, manual citation checks, source mentions, assisted conversions. |
Do not make these claims:
- Schema guarantees ChatGPT or Perplexity citations.
- A page must rank first in Google to be cited.
- Any vendor can force a citation.
- Publishing large volumes of generic content improves citation odds.
- Social traction automatically becomes durable search discoverability.
Use crawler access as an intentional policy decision. OpenAI provides documentation for GPTBot, OAI-SearchBot, and broader bot controls. Review robots.txt before changing access. Do not block or allow crawlers by accident.
How to audit technical web3 SEO before creating more content
Run the technical audit before publishing more articles. A crawler cannot cite or rank a page it cannot reach, render, index, or understand.
Start with the official site, docs home, API reference, token page, governance page, security page, ecosystem page, and top blog articles. These pages carry the highest discovery and trust value.
Use this audit sequence:
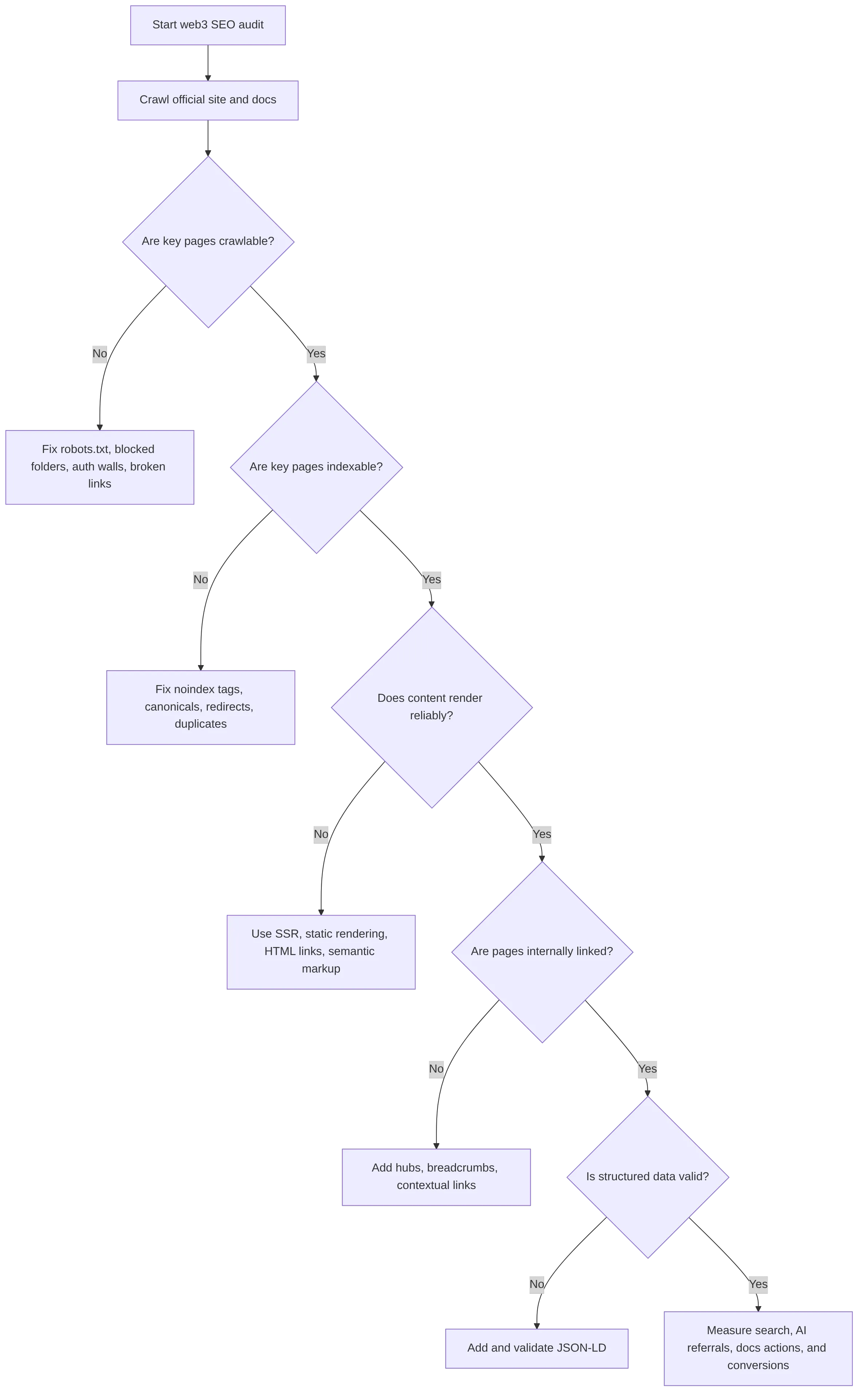
Use this technical checklist:
| Check | What to inspect | Action |
|---|---|---|
| robots.txt | Blocked folders, docs paths, blog paths, bot rules. | Allow important public pages intentionally. Block only what should not be accessed. |
| Sitemap.xml | Canonical, indexable, live URLs only. | Remove redirected, noindex, duplicate, or broken URLs. Follow Google's sitemap guidance. |
| Canonicals | Duplicate pages across main site, docs, blog, Medium, Mirror, or regional URLs. | Point each duplicate set to the correct official canonical page. |
| JavaScript rendering | Raw HTML compared with rendered HTML. | Put core content and links in crawlable output. Follow Google's JavaScript SEO guidance. |
| Internal links | Orphan pages, deep pages, unclear anchor text. | Link from homepage, hubs, docs, blog, glossary, and ecosystem pages. |
| Core Web Vitals | LCP, INP, CLS on templates, not only homepage. | Test docs, article, token, and app-adjacent pages using Google's Core Web Vitals guidance. |
| Structured data | Organization, Article, BreadcrumbList, FAQPage, TechArticle, SoftwareApplication where suitable. | Validate markup with Schema Markup Validator and Google's Rich Results Test. |
| Hreflang | Language and region alternates. | Use reciprocal annotations for multilingual sites. Follow Google's localized versions documentation. |
| Search diagnostics | Indexing, crawl errors, impressions, queries. | Use Google Search Console and Bing Webmaster Tools. |
Use JavaScript checks carefully. Many Web3 websites are built like applications. That is acceptable for product functionality, but risky for public information pages. Protocol explanations, docs links, integration pages, and security details should not depend only on client-side rendering.
Use a priority model instead of fixing everything:
| Priority | Condition | Response |
|---|---|---|
| P1 | Blocks crawling, indexing, rendering, or conversion on core pages. | Fix immediately. |
| P2 | Affects protocol, token, docs, security, governance, or main commercial pages. | Schedule within 30 to 60 days. |
| P3 | Supports topical authority, glossary depth, regional growth, or future content clusters. | Add to the growth roadmap. |
| Backlog | Has low impact on discovery, trust, or conversion. | Deprioritize. |
SeekLab.io follows this prioritization logic in technical work. Its technical SEO audit guidance covers crawlability, indexing, Core Web Vitals, JavaScript compatibility, schema, internal links, and performance issues. Its SEO audit checklist for 2026 provides a broader review structure for teams that need a step-by-step diagnostic process.
Get a free audit report if you need to know whether your Web3 site, docs, and blog are crawlable, indexable, renderable, and ready for citation-oriented discovery.
How to build web3 SEO content that AI answer engines can verify
Create official pages before publishing opinion articles. AI answer engines need stable facts, not scattered commentary.
Use this page template for important Web3 entities:
| Page section | Required content | Reason |
|---|---|---|
| Direct answer block | Two or three sentences defining the project, feature, token, protocol, or integration. | Helps extraction and reduces ambiguity. |
| Entity details | Names, supported chains, product modules, audience, use cases, official links. | Clarifies what the page represents. |
| Evidence section | Docs, audits, governance records, partner references, changelog entries. | Supports verification. |
| Structured table | Token details, API versions, integrations, feature differences, regional availability. | Makes facts easy to scan and summarize. |
| Internal links | Docs, glossary, security, governance, ecosystem, contact or partnership page. | Builds semantic relationships. |
| Update date | Last reviewed date or version note. | Reduces stale information risk. |
| FAQ | Visible answers for common search and AI-style questions. | Supports conversational discovery. |
| Conversion step | Docs link, developer signup, ecosystem application, partnership inquiry, contact route. | Turns discovery into action. |
Use content types based on intent:
| Searcher | Page type | Practical content |
|---|---|---|
| Developer | API guide, SDK tutorial, troubleshooting page. | Install steps, code examples, version notes, changelog links. |
| Partner | Integration page, ecosystem page, partnership page. | Use cases, supported workflows, proof links, contact route. |
| User | Product explainer, FAQ, glossary, comparison page. | Plain-language definitions, limitations, risk notes. |
| Community member | Governance page, roadmap page, proposal explainer. | Voting process, records, forum links, update history. |
| Security reviewer | Security page, audit page, disclosure policy. | Audit references, bug bounty details, incident policy if applicable. |
Add structured data only when it matches visible content. Google's structured data introduction explains how structured data helps search engines understand pages. Google's structured data policies require markup to reflect visible page content. Schema vocabulary is available at Schema.org.
Recommended schema candidates:
| Page type | Schema candidates |
|---|---|
| Homepage | Organization, WebSite |
| Blog article | Article, BreadcrumbList |
| FAQ page | FAQPage |
| Developer tutorial | TechArticle, BreadcrumbList |
| Software or protocol product page | SoftwareApplication or Product where appropriate |
| Glossary entry | DefinedTerm where appropriate |
| Docs hierarchy | BreadcrumbList |
| Ecosystem list | ItemList |
Do not use schema to describe content that users cannot see. Do not mark a page as FAQPage unless the questions and answers are visible. Do not mark unsupported claims as facts.
Build content clusters around the official site architecture:
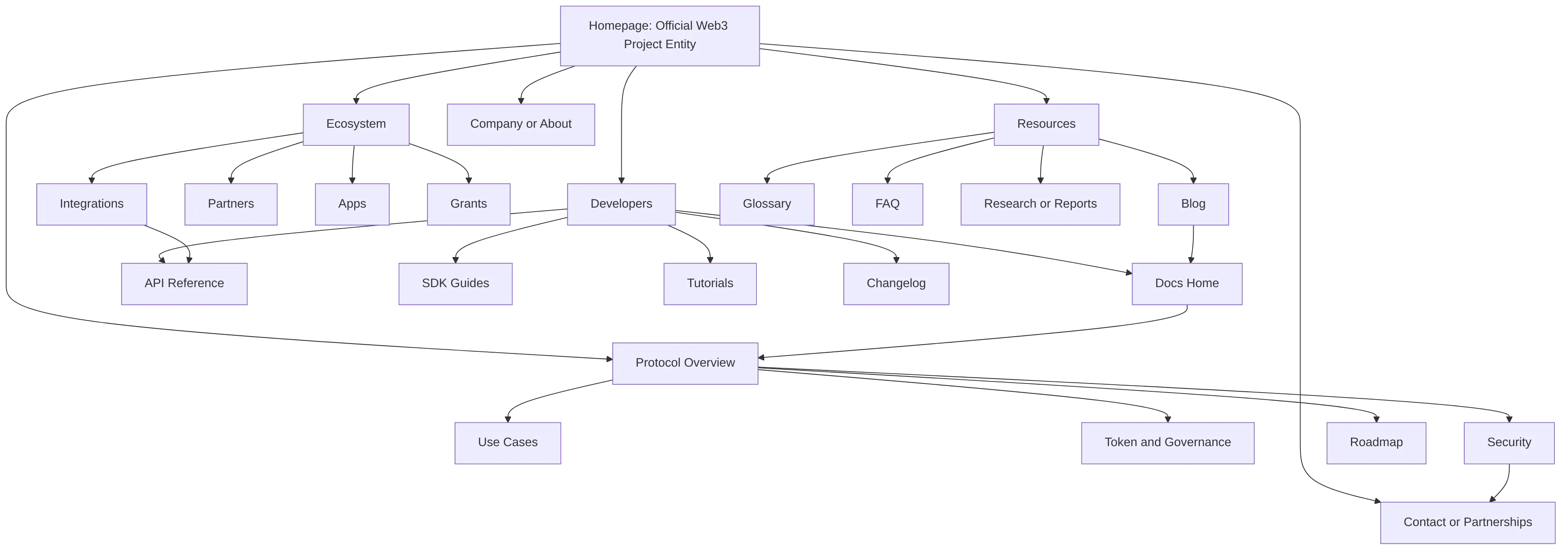
Use visuals where they explain technical relationships. Web3 pages often need diagrams for architecture, bridging, validator roles, developer onboarding, and governance flows. Generic images do not help citation readiness. A useful image should explain a concept that a reader would otherwise need several paragraphs to understand.
Use trend-driven content only after the technical foundation is stable. Early topic selection is useful when it becomes a structured content cluster with internal links, source-backed pages, and conversion paths. SeekLab.io's approach to hot topic analysis for search-led content planning is relevant when Web3 teams need to spot topics before they become crowded. Its example of trend-driven content architecture shows the same principle: a trend is useful only when it is converted into pages that search engines, AI systems, and users can understand.
Refresh content by risk level:
| Page type | Review frequency | Reason |
|---|---|---|
| Token, contract, bridge, security, governance | Monthly or whenever material facts change. | These pages carry trust and risk implications. |
| Docs, API, SDK, changelog | Per release cycle. | Developers need current implementation details. |
| Use cases, integrations, ecosystem pages | Monthly or quarterly. | Partners and product coverage change. |
| Glossary, FAQs, explainers | Quarterly. | Definitions and user language shift. |
| Multilingual pages | After each major source-language update. | Regional facts must stay consistent. |
How to measure web3 SEO progress without overclaiming citations
Measure citation readiness as a combined search, source, and conversion system. Do not report only rankings. A Web3 project may increase impressions while still failing to produce developer signups, wallet actions, ecosystem applications, or partner inquiries.
Use this dashboard:
| Metric group | What to track | Tool or method |
|---|---|---|
| Search visibility | Impressions, clicks, average position, indexed pages, crawl errors. | Google Search Console and Bing Webmaster Tools. |
| Technical health | Crawlability, rendering, Core Web Vitals, sitemap status, canonical errors. | Site crawler, PageSpeed Insights, URL inspection. |
| Citation observation | Manual prompt checks for priority questions, observed sources, citation frequency by topic. | Controlled prompt log. |
| AI referral traffic | Referrals from detectable AI answer platforms where analytics shows them. | Analytics and server logs. |
| Docs engagement | API views, tutorial visits, changelog visits, SDK download clicks, docs search queries. | Docs analytics and product analytics. |
| Content quality | Pages with answer blocks, update dates, structured tables, source references, internal links. | Manual content audit. |
| Conversion | Wallet connects, developer signups, grant applications, ecosystem submissions, contact forms, partnership inquiries. | Analytics events and CRM review. |
| Regional performance | Language pages indexed, hreflang errors, market-level queries, regional conversions. | Search Console, hreflang audit, analytics. |
Manual citation checks must be controlled. Use the same prompt wording, region, language, date, and account state when possible. Log whether the project appears, whether the official site is cited, which page is cited, and whether the answer is accurate. Treat the log as directional evidence, not a guaranteed platform report.
A useful six-month roadmap looks like this:
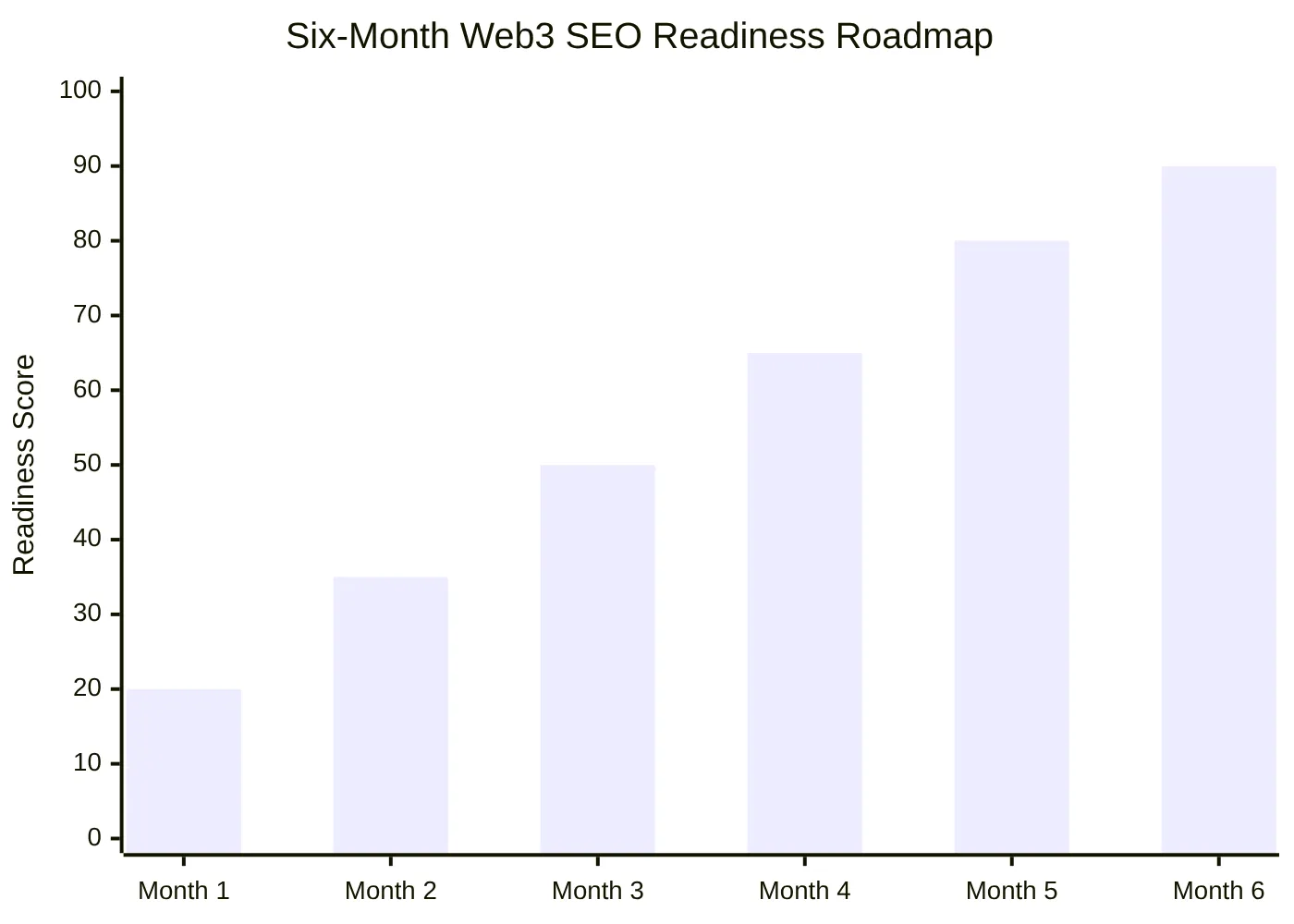
Use the months as operational phases:
| Month | Workstream | Output |
|---|---|---|
| Month 1 | Crawl audit, rendering checks, robots.txt, sitemap, canonical review. | Technical issue list with P1/P2/P3 priorities. |
| Month 2 | Entity architecture, internal linking, structured data plan. | Protocol, token, docs, security, governance, and ecosystem page map. |
| Month 3 | Docs SEO refresh and developer tutorials. | Improved API, SDK, changelog, troubleshooting, and tutorial pages. |
| Month 4 | Citation-ready content cluster. | FAQs, glossary, comparisons, use cases, diagrams, answer blocks. |
| Month 5 | Third-party corroboration and trust pages. | Partner references, security references, governance records, source-backed claims. |
| Month 6 | Multilingual rollout and reporting. | Hreflang validation, regional pages, monthly performance review. |
Use third-party mentions as corroboration, not as a shortcut. Good references can include credible industry media, ecosystem partner pages, official conference pages, security firms, developer community resources, and public documentation. Avoid low-quality paid mentions, unsupported claims, hidden text, doorway pages, and manipulative link tactics.
For multilingual Web3 projects, prioritize markets where the project has real business or community activity. SeekLab.io works across major regions, including the Asia-Pacific region, the United States, and Europe, with teams and legal entities in Singapore and Shanghai and a BD team in Dubai. Regional SEO should include hreflang, localized examples, consistent URL patterns, and regional conversion paths.
Contact us if your official site, docs, blog, and ecosystem pages are fragmented and you need a prioritized roadmap before investing in more content.
How SeekLab.io supports web3 SEO execution responsibly
SeekLab.io helps brands build search visibility and AI-era discoverability through high-quality content production and technical optimization. The work focuses on making websites easier for search engines, AI systems, and real users to understand by improving content structure, information clarity, page architecture, internal linking, and site readiness.
Use SeekLab.io when the problem spans technical SEO, content strategy, documentation structure, multilingual architecture, and conversion. Web3 projects often have all of these problems at once. A crawl report alone is not enough if the protocol page is unclear, the docs are orphaned, and the blog does not connect to developer or partner actions.
SeekLab.io can support:
- Full-site crawling and structured analysis.
- Core Web Vitals and page performance diagnostics.
- Indexing, crawling, rendering, and JavaScript compatibility checks.
- Sitemap.xml and robots.txt validation.
- Internal link equity and semantic structure analysis.
- Schema data compliance and enhancement.
- AI search friendliness and citation readiness evaluation.
- Website tech stack analysis.
- Topic selection based on user intent and contextual scenarios.
- Brand and industry knowledge base integration.
- SERP and AI-generated answer structure analysis.
- High-quality blog creation with images, tables, internal links, headings, meta tags, and JSON-LD.
- Multilingual site architecture for international search opportunities.
- Monthly data review and performance reporting.
The work should start with strategic decisions. Do not fix every small SEO issue because a crawler found it. Do not publish articles before confirming the topic belongs on the site architecture. Do not chase trends before deciding which page should own the entity, keyword, user intent, and conversion path.
SeekLab.io does not need to position web3 SEO as a citation hack. The practical promise is narrower and more useful: identify what affects growth, deprioritize what does not, improve the technical foundation, create trustworthy content assets, and connect discovery to measurable business outcomes.
Get a free audit report if you need a clear view of crawlability, rendering, indexing, internal links, schema, content structure, and citation readiness. Contact us if traffic is not becoming developer adoption, ecosystem participation, or qualified partnership inquiries.
FAQ:
| Question | Answer |
|---|---|
| Can ChatGPT or Perplexity citations be guaranteed? | No. No public documentation provides a guaranteed citation formula. The practical goal is to improve accessibility, clarity, verification, freshness, and authority. |
| Does schema make ChatGPT cite a Web3 site? | No. Schema can help search engines understand page types and entities, but it does not guarantee AI answer citations. It must match visible content. |
| Should Web3 projects publish on Medium or their own domain? | Publish important official information on the project domain first. Third-party platforms can be used for distribution, but they should not replace canonical official pages. |
| Is web3 SEO only about token keywords? | No. It includes protocol pages, developer docs, API tutorials, governance, security, ecosystem pages, glossary content, integration pages, and conversion paths. |
| How often should Web3 content be updated? | Update token, security, governance, and contract pages whenever facts change. Review docs by release cycle and review glossary, FAQ, and regional pages on a scheduled basis. |
| What should a Web3 team fix first? | Fix anything that blocks crawling, indexing, rendering, or conversion on core pages. Then improve entity pages, documentation, structured content, internal links, and measurement. |


