How to Get Your Website Cited by Perplexity AI: The Two-Gate Problem
Expert reviewed

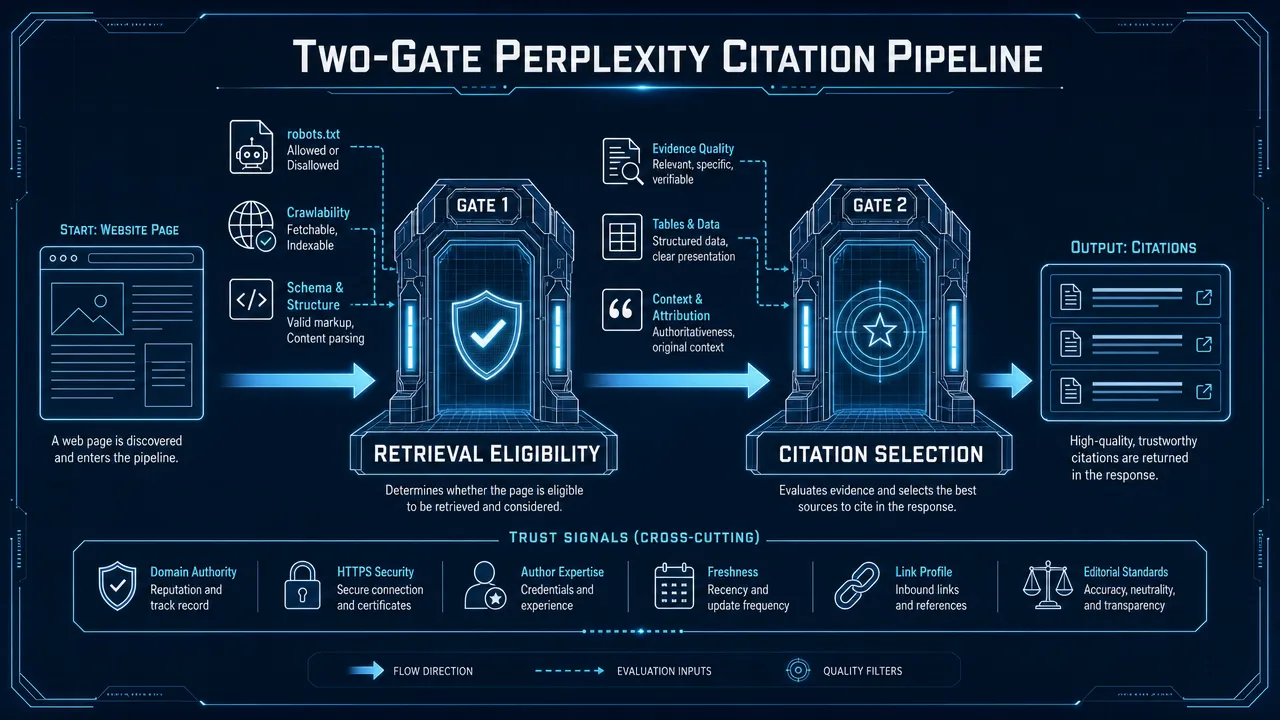
To get your website cited by Perplexity AI, your page first needs to be retrievable, then it needs to be worth citing. That is the Two-Gate Problem behind Perplexity AI citations: technical eligibility opens the door, but citation selection depends on whether the page is specific, trustworthy, current, and easy to use as a source.
This case study breaks the problem into a practical diagnostic workflow for independent websites, B2B service sites, exporter websites, SaaS documentation, and multilingual brand sites. You will see what to check first, which issues can block retrieval, what makes a page citation-ready, and why traditional SEO rankings alone do not guarantee that your website will get cited in Perplexity AI.
The practical components are simple: audit crawlability, robots.txt, indexability, canonicals, JavaScript rendering, internal links, sitemap quality, schema, multilingual signals, direct answer quality, evidence, freshness, and conversion paths. The goal is not to promise citations. The goal is to make the right pages easier for search engines, AI systems, and real buyers to understand.
What Perplexity AI citations mean in this case study
Perplexity AI citations are source links shown inside or alongside AI-generated answers. Perplexity publicly positions citations as part of its answer experience, and its own documentation describes citation handling in generated responses. The official Perplexity streaming citation documentation explains how citations can be parsed from API responses, while the Perplexity Publishers' Program announcement frames citations as a way to credit sources and build trust.
For a website owner, the important distinction is this: a citation is not the same as a traditional blue-link ranking. A traditional search result is a destination the user chooses from a list. A Perplexity citation supports a generated answer. Your page might be used because one section, table, definition, comparison, or data point directly supports the response.
That changes the optimization target. A page does not only need to rank. It needs to be retrievable, understandable, and useful at the passage level. A long article that hides the answer under vague introductions may be less useful than a shorter page with a precise definition, comparison table, updated examples, and credible references.
For independent websites, this is commercially important. A buyer may see your brand as a cited source before visiting your site. That can shape trust early in the decision process, especially for technical services, B2B products, international trade, SaaS documentation, or category education. This is where AI search visibility, Perplexity AI answer citations, and conversion-focused SEO start to overlap.
A realistic example: a B2B service page may rank for a commercial phrase, but Perplexity may not cite it if the page only says "we provide professional solutions" without explaining methodology, constraints, deliverables, examples, or evidence. The page exists, and it may even be indexed, but it is not a strong source.
Perplexity AI citations and the Two-Gate diagnosis
The Two-Gate Problem separates eligibility from selection.
| Gate | Main question | Common failure | Practical implication |
|---|---|---|---|
| Gate 1: Retrieval eligibility | Can Perplexity or related retrieval systems access, crawl, render, and interpret the page? | Blocked robots.txt rules, noindex tags, broken canonicals, JavaScript-hidden content, orphan URLs | The page may never enter the candidate source pool |
| Gate 2: Citation selection | Is the page useful enough to support an AI-generated answer? | Generic copy, weak evidence, outdated content, unclear entities, no direct answer | The page may be retrieved but not cited |
The key mistake is treating these two gates as one problem. Technical teams may assume that if a page is indexable, the content team has done enough. Content teams may assume that if an article is detailed, technical access is not a problem. In practice, both assumptions fail often.
A JavaScript-heavy SaaS documentation page can contain excellent answers, but if the core text only appears after unreliable client-side rendering, retrieval systems may miss it. An exporter website can publish dozens of translated product pages, but if hreflang and canonicals conflict, the wrong market page may be selected or ignored. A service brand can publish a polished article, but if it contains no evidence, no examples, and no clear definitions, it gives Perplexity little reason to cite it.
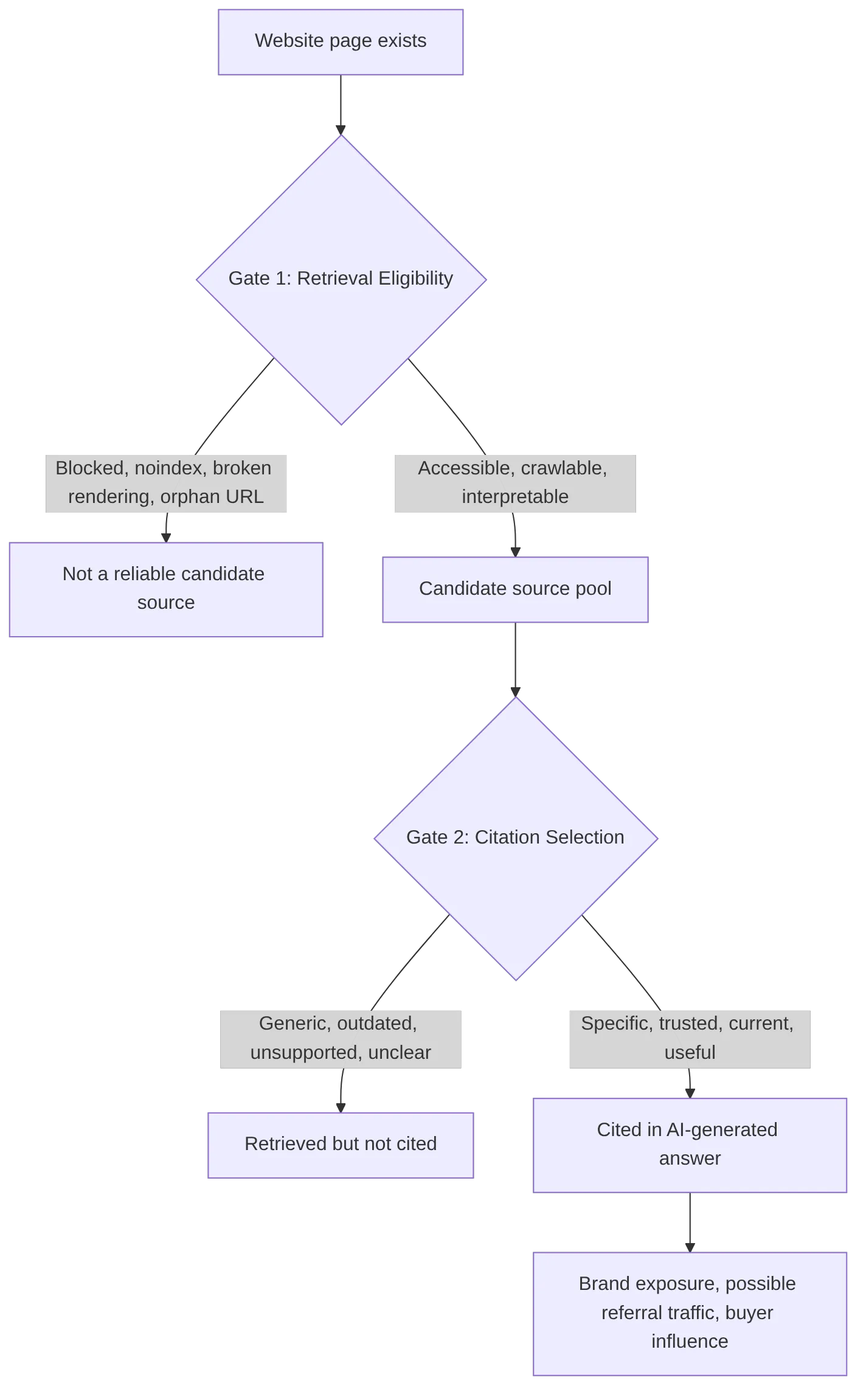
This is the diagnostic model SeekLab.io uses when evaluating citation readiness. The work is not limited to technical issue detection. It includes page architecture, content structure, internal linking, information clarity, topic selection, technical SEO, schema readiness, multilingual architecture, and whether the page can realistically support business outcomes.
The strongest starting question is not "How do we force Perplexity to cite us?" It is "Which exact answer should this page be a trustworthy source for?" Without that decision, a team may spend weeks writing content that is polished but directionless.
Perplexity AI citations Gate 1: retrieval eligibility checklist
Gate 1 is where many websites lose before content quality is even evaluated. The official Perplexity crawler documentation describes PerplexityBot and Perplexity-User, including guidance for sites that want to appear in Perplexity search results. Site owners should review these rules alongside standard crawl and indexation checks.
The practical point is not to blindly allow every crawler or block every crawler. It is to align access rules with business goals. If your brand wants to be cited by AI search engines, you need to know whether your important pages are accessible, indexable, renderable, and internally connected.
| Priority | Check | What can go wrong | What to do first |
|---|---|---|---|
| P1 | Crawlability | Important folders are blocked, pages return 4xx or 5xx, login walls hide useful content | Crawl the site and inspect status codes for priority URLs |
| P1 | Robots.txt | /blog/, /resources/, locale folders, JS, or CSS files are blocked unintentionally |
Compare robots.txt rules against intended citation pages |
| P1 | Indexability | Pages have accidental noindex tags or X-Robots-Tag rules | Inspect templates, not just individual URLs |
| P1 | Canonicals | Pages canonicalize to the homepage, wrong language version, or duplicate URL | Confirm each important page points to the intended canonical URL |
| P1 | JavaScript rendering | Main content appears only after scripts run | Compare raw HTML with rendered HTML |
| P2 | Internal links | Useful pages are orphaned or buried too deep | Link from hubs, service pages, category pages, and related articles |
| P2 | Sitemap.xml | Sitemap includes redirected, noindex, or non-canonical URLs | Keep only canonical, indexable, important URLs |
| P2 | Schema and JSON-LD | Invalid schema, duplicate entities, or markup that does not match visible content | Validate Organization, Article, BreadcrumbList, FAQPage, Product, or Service schema where relevant |
| P2 | Multilingual signals | Hreflang return tags are missing, canonicals conflict, machine-translated pages duplicate each other | Fix architecture before scaling translation |
| P3 | Page performance | Heavy scripts and slow templates reduce crawl efficiency and user experience | Test important templates, not only the homepage |
For JavaScript-heavy websites, the raw HTML versus rendered HTML comparison is often revealing. If the raw HTML contains only a shell and the key answer appears later through scripts, the page may be harder to retrieve and interpret. SeekLab.io has a separate guide on JavaScript SEO and indexing checks that is especially relevant for SaaS, technical documentation, and modern front-end websites.
Schema is useful, but it is not a magic fix. If a page is noindex, blocked, canonicalized away, or invisible in the initial HTML, adding JSON-LD will not solve the core problem. Schema should clarify entities after the basic retrieval path is clean. For a deeper technical view, see SeekLab.io's guide to schema markup and JSON-LD audit.
For multilingual websites, Gate 1 gets more fragile. Exporters and international brands often add translated pages before validating hreflang, canonicals, localized URL structure, and language consistency. That can create a large site that looks international to humans but confusing to search engines and AI systems. SeekLab.io's guide to multilingual SEO architecture covers this problem in more detail.
If you are unsure where your pages fail, a free SEO audit report can help identify crawlability, sitemap, robots.txt, indexability, canonical, hreflang, performance, structured data, heading, duplication, and orphan-page issues. The useful part is prioritization: not every issue deserves immediate attention, but the ones that block retrieval should be handled before content expansion.
Perplexity AI citations Gate 2: citation selection checklist
Passing Gate 1 only means the page can become a candidate. Gate 2 asks whether the page deserves to be cited. This is where many keyword-driven articles fail. They target a phrase, but they do not provide a clean answer, a useful distinction, a table, an example, or a credible reference.
The official Google guidance on creating helpful content is not Perplexity-specific, but its core principles apply well: content should be useful, reliable, and made for people. For answer engines, that translates into content that can be quoted, summarized, verified, and trusted.
| Citation selection factor | Weak page pattern | Citation-ready page pattern |
|---|---|---|
| Direct answer quality | Long intro before saying anything useful | Clear answer in the first section |
| Specificity | Generic phrases like "best solution" or "professional service" | Concrete criteria, use cases, limits, and examples |
| Evidence | Unsupported claims and no references | Links to official documentation, standards, data, or methodology |
| Entity clarity | Unclear brand, product, author, location, or service definition | Consistent names, author details, company context, schema |
| Original insight | Rewritten competitor advice | Research, teardown findings, field observations, comparison criteria |
| Freshness | Old screenshots, outdated terms, no update date | Maintained content with visible updates where needed |
| Structure | Walls of text | H2/H3 hierarchy, tables, FAQs, summaries, definitions |
| Conversion fit | Cited page has no next step | Internal links, related resources, inquiry path, clear service relevance |
A practical before-and-after example helps. A weak exporter page might say, "We provide high-quality packaging products for global customers." That gives an answer engine almost nothing to cite. A stronger page would define packaging materials, compare use cases, explain export considerations, show a specification table, include regional terminology, and link to relevant official standards where appropriate.
The same applies to B2B service websites. A page about technical SEO services becomes more citation-ready when it explains the audit process, shows what gets checked, distinguishes critical issues from lower-priority warnings, and describes which fixes affect growth. SeekLab.io's guide on how to read a technical SEO audit report is useful because it shows how issue severity and prioritization can be structured.
Here is a practical scoring model website teams can use before publishing or refreshing a page. It is not Perplexity's algorithm. It is a business-friendly way to assess whether a page is likely to be useful as a source.
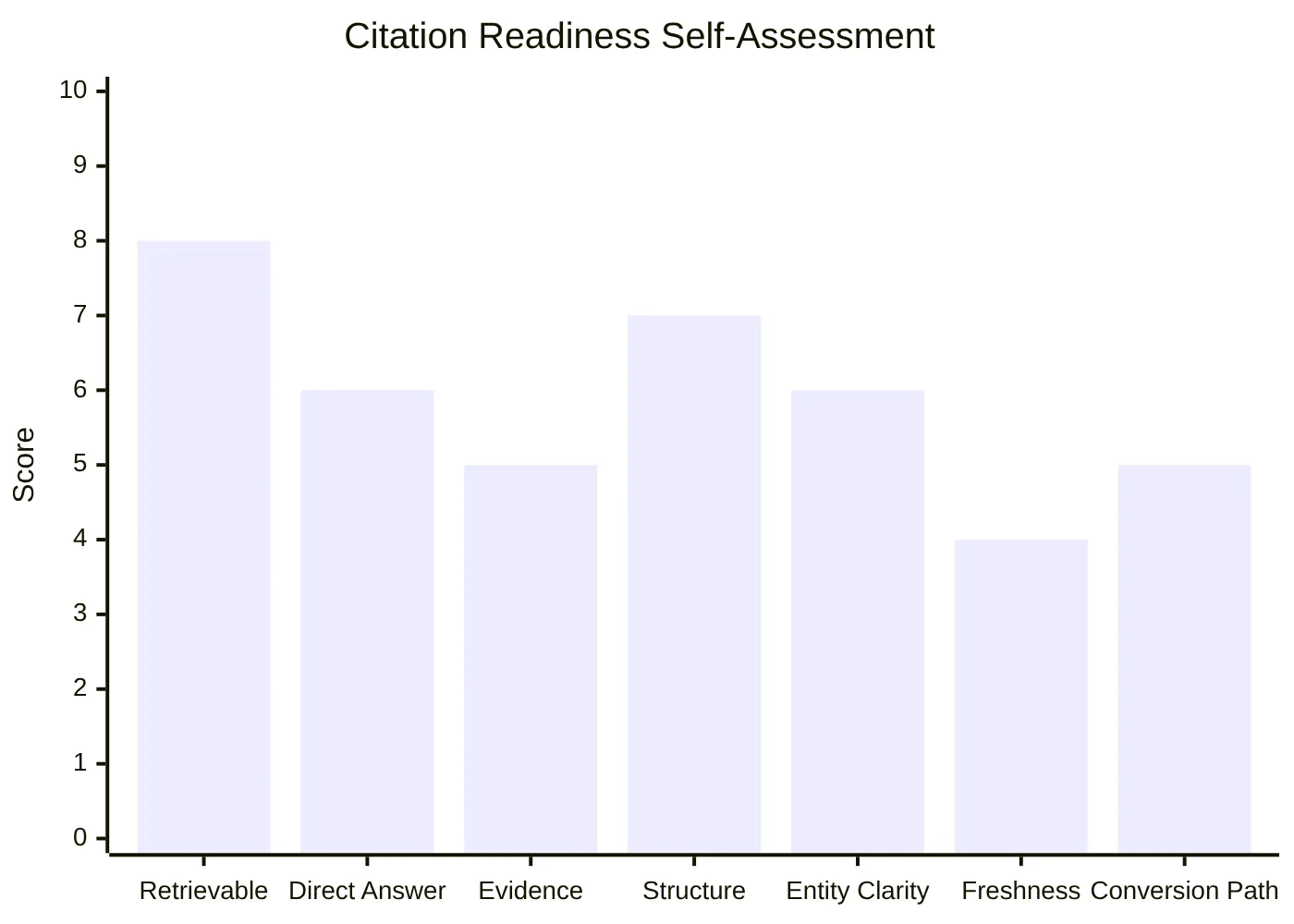
In this sample, retrieval is reasonably strong, but freshness and evidence are weak. That means the next improvement should not be another keyword variation. It should be adding better references, updating outdated details, clarifying methodology, and making the answer easier to extract.

Perplexity AI citations vs traditional SEO: what changes
Perplexity AI SEO overlaps with traditional SEO, but the job is not identical. Traditional SEO focuses on rankings, impressions, clicks, and conversions from search results. Perplexity citation optimization focuses on whether your page can support an answer generated by an AI search system.
This changes the unit of usefulness. In traditional SEO, the whole page competes for a query. In Perplexity, a specific passage, table, definition, comparison, or statistic may be the useful part. That is why a page with one excellent answer block may be more citation-ready than a longer article that buries the useful content.
| Dimension | Traditional SEO | Perplexity citation readiness |
|---|---|---|
| Main output | Organic ranking and click opportunity | Source citation inside an answer |
| User behavior | User scans results and chooses a page | User reads an answer and may inspect citations |
| Useful unit | Page-level relevance | Passage-level support |
| Content emphasis | Search intent coverage | Direct answer, evidence, extractability |
| Technical emphasis | Crawl, index, render, canonicalize | Same foundation, plus accessible answer passages |
| Measurement | Rankings, impressions, CTR, leads | Citation presence, answer influence, referral quality, assisted conversions |
| Main risk | Traffic without inquiries | Citation without a useful page journey |
The measurement problem is also different. A Perplexity citation may influence a buyer without generating an immediate click. A procurement manager may see your company cited in an answer, recognize the brand later, and then search directly. That makes it risky to judge success only by last-click referral traffic.
Still, this does not mean websites should chase citations at any cost. A citation on a page that has no product clarity, no trust signals, and no conversion path may produce little business value. For SeekLab.io's audience, especially independent websites and official company websites, the better target is cited by AI search engines in a way that supports credibility and inquiry quality.
There is also a ranking misconception to avoid. Ranking first in Google does not guarantee a Perplexity citation. It may help retrieval in some situations, but Perplexity's exact Perplexity AI source ranking and citation selection system is not publicly disclosed. The safest wording is that technical SEO, answer clarity, authority, freshness, and evidence may improve citation readiness. They do not guarantee citation placement.
The same caution applies to schema. Structured data can help machines understand entities and page meaning, and Google's structured data documentation explains its role in search features. But no public Perplexity source confirms that schema directly causes citations. Treat schema as a clarity layer, not a shortcut.
How SeekLab.io helps improve Perplexity AI citations readiness
For a website trying to optimize for Perplexity AI, the right workflow starts before writing. The first decision is the answer opportunity: which question, comparison, definition, checklist, risk, or methodology should your page be a credible source for?
A practical workflow looks like this:
- Identify answer opportunities where buyers ask real questions, not just broad keywords.
- Review current Perplexity AI answer citations and note which source types appear.
- Audit technical retrieval: crawlability, robots.txt, noindex, canonicals, rendering, sitemap, internal links, and page performance.
- Improve page structure with direct answers, headings, tables, summaries, FAQs, and examples.
- Add evidence from official sources, standards, documentation, original research, or clearly explained methodology.
- Strengthen entity clarity with consistent brand, product, service, location, author, and organization signals.
- Add valid schema and JSON-LD where it matches visible page content.
- Build internal links from relevant hubs, service pages, product pages, and supporting articles.
- Refresh content when facts, screenshots, product names, or market assumptions change.
- Review conversion quality, not only rankings or citation presence.
This is where SeekLab.io's work fits naturally. SeekLab.io helps brands build search visibility and AI-era discoverability through high-quality content production and technical optimization. The work covers full-site crawling, Core Web Vitals and performance diagnostics, indexing and rendering checks, JavaScript compatibility, internal link equity, semantic structure, schema compliance, sitemap.xml and robots.txt validation, multilingual site architecture, AI search friendliness, and citation readiness evaluation.
The value is not "fix everything." Many websites have hundreds of warnings, but only a smaller set truly affects growth. SeekLab.io focuses on identifying what matters, what can be deprioritized, and what should be handled before the team spends more money on content.
For content, SeekLab.io does not treat topic selection as a list of keywords. The process looks at user intent, contextual scenarios, SERP and AI-generated answer structures, brand knowledge, industry details, and conversion goals. Articles are planned to include structured layouts, headings, meta tags, JSON-LD, internal links, images, tables, and practical evidence where appropriate. That matters because Perplexity AI citations reward source usefulness, not empty length.
For international brands, SeekLab.io also supports multilingual site architecture across markets including the Asia-Pacific region, the United States, and Europe, with teams and legal entities in Singapore and Shanghai and a BD team based in Dubai. This matters for exporter websites and cross-border companies because citation readiness can break at the localization layer: wrong hreflang, duplicated translated pages, unclear product terminology, or mismatched regional intent.
If your website is not being cited, do not assume the problem is only content quality or only technical SEO. Diagnose both gates:
| Symptom | Likely gate problem | What to check |
|---|---|---|
| Important pages do not appear in search at all | Gate 1 | Robots.txt, noindex, canonicals, sitemap, server status, internal links |
| Page is indexed but never cited | Gate 2 | Direct answer quality, evidence, structure, freshness, trust signals |
| Multilingual pages compete with each other | Gate 1 and Gate 2 | Hreflang, canonicals, local examples, translated terminology |
| Traffic grows but inquiries do not | Post-citation conversion problem | Page journey, offer clarity, proof, contact path, buyer objections |
| Content sounds polished but generic | Gate 2 | Examples, methodology, original insight, tables, definitions |
The next step should be a practical diagnosis, not another batch of generic articles. If you need to know whether your pages are technically retrievable and content-ready, start with a free SEO audit report. If the issue is broader than technical checks, review SeekLab.io's SEO and answer-ready content services or contact SeekLab.io for technical guidance and citation-ready content planning.
FAQ
What is the Two-Gate Problem for Perplexity AI citations?
The Two-Gate Problem is SeekLab's framework for diagnosing why websites fail to get cited by Perplexity AI. Gate 1 is retrieval eligibility — can Perplexity's crawler find, access, render, and interpret the page? Gate 2 is citation selection — is the page useful enough to support an AI-generated answer? Most websites that fail to get cited are stuck at Gate 1 and never reach the content quality evaluation. Brands that clear Gate 1 but still don't appear in citations are typically failing at Gate 2.
Does Perplexity AI have its own crawler?
Yes. Perplexity uses two main crawlers: PerplexityBot for search-related retrieval and Perplexity-User for real-time browsing. The official Perplexity crawler documentation explains each crawler's purpose and how site owners can control access through robots.txt. Blocking PerplexityBot removes your pages from citation eligibility before content quality is even evaluated.
Does ranking on Google guarantee Perplexity will cite you?
No. Ranking highly on Google may help retrieval in some situations, but Perplexity's citation selection system is not publicly disclosed and does not directly mirror Google rankings. A page can rank #1 on Google and never appear in a Perplexity citation if it fails Gate 2 — weak evidence, vague answers, no direct content extraction points, or outdated information.
What content structure gets cited most by Perplexity?
Pages with a direct answer in the first section, specific verifiable data points, comparison tables, FAQ sections in Q&A format, and clear entity signals (brand name, service category, location, author) are the most consistently cited. Generic introductory paragraphs, vague claims like "we provide professional solutions," and content with no external references are the weakest for Perplexity citation purposes.
How long does it take to start getting Perplexity citations?
Based on SeekLab's campaign data, AI citations typically begin appearing 6-8 weeks after well-structured content is published on a site with adequate technical foundations. This is part of what SeekLab calls the Citation Lag Problem — there is a delay between publishing and citation that most teams don't account for. Citations also decay 3-4 weeks after publishing activity slows.
Is schema markup required for Perplexity citations?
No. Schema markup can help machines understand entities and page structure, but no public Perplexity documentation confirms that schema directly causes citations. Treat schema as a clarity layer — useful after the basic retrieval path is clean, but not a substitute for fixing crawlability, indexability, or content quality issues first.
What is the difference between a Perplexity citation and a Perplexity mention?
A Perplexity citation is a linked source shown inside or alongside an AI-generated answer — your website URL is listed as a reference. A Perplexity mention is when your brand name appears in the answer text without necessarily linking to your site. Both matter for brand visibility, but citations carry more trust signal and are more directly trackable.
The reliable takeaway is simple: to improve your chances of earning Perplexity AI citations, build pages that pass both gates. Make them accessible enough to be retrieved, then useful enough to be selected. That means clean technical foundations, clear entities, direct answers, evidence, internal links, schema where appropriate, and content that helps a real buyer make a better decision.


