What is llms.txt? The Honest 2026 Guide
Expert reviewed

llms.txt is a proposed Markdown file placed at a website root to summarize the site and point large language model systems toward important public resources. The honest 2026 answer is simple: it can help clarify your best content for machine readers, but it is not an official web standard, not a confirmed Google ranking factor, and not a replacement for robots.txt, sitemap.xml, schema markup, or strong page architecture.
For website teams, the useful decision is not "Can we publish an llms.txt file?" The useful decision is "Are the pages we would highlight actually indexable, current, canonical, and strong enough to represent the business?" A clean llms.txt file can support AI crawler guidance and LLM website indexing in a loose, emerging sense, but it cannot repair thin product pages, broken internal links, poor multilingual structure, or JavaScript-rendered content that crawlers cannot reliably read.
What llms.txt is and why it is only guidance in 2026
llms.txt is best understood as a curated site guide for language-model systems. The original llms.txt proposal describes a Markdown file, usually available at /llms.txt, that helps LLMs understand and use website information. The related Answer.AI explanation frames it as a way to provide useful context at inference time, especially when a model or retrieval system needs concise information about a site.
A typical llms.txt file lives at a root path such as https://example.com/llms.txt. It usually contains a site title, a short summary, grouped sections, and Markdown links to important pages. For a B2B company, that might mean company overview, product categories, technical documentation, certifications, service pages, blog hubs, and contact pages. It should not be a dump of every URL in the CMS.
The key limitation is status. The llms.txt standard is not a formal standard in the same sense as established web protocols. It is a proposed convention with visible community interest, especially among documentation platforms and SEO practitioners, but public documentation from major crawlers still centers on robots.txt, crawler user agents, and existing search infrastructure.
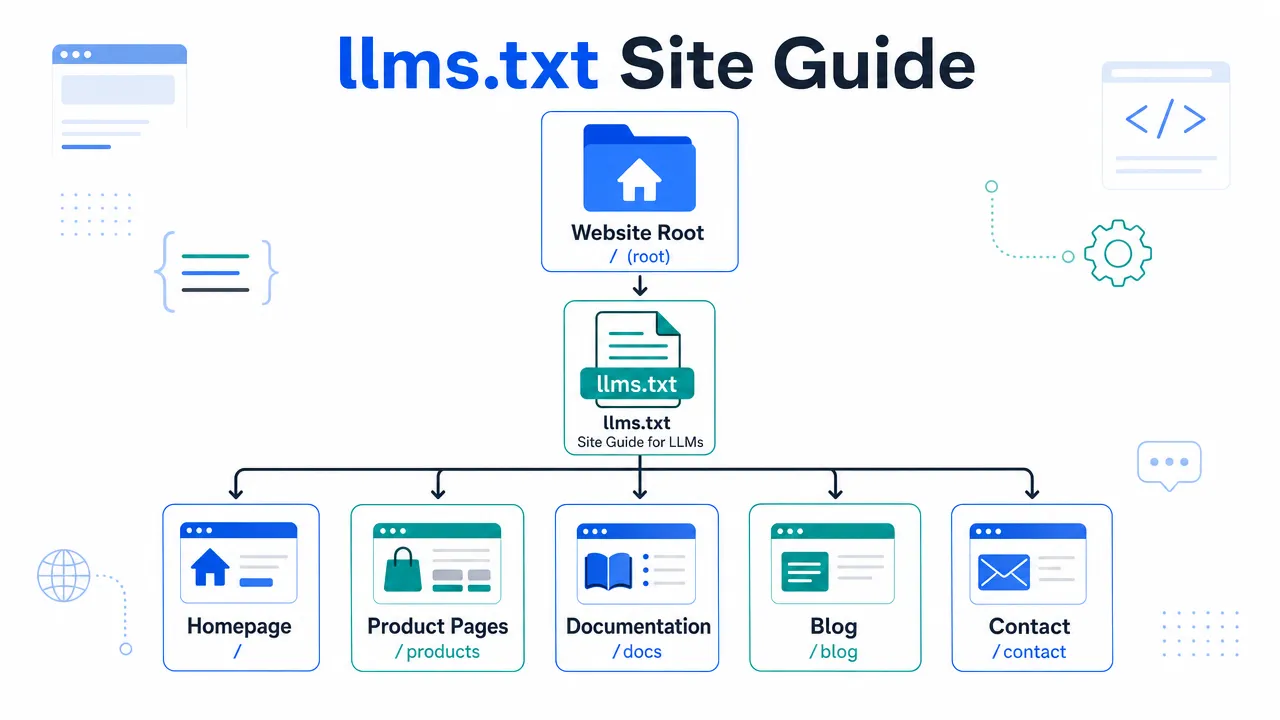
A practical llms.txt implementation usually follows this pattern:
| Section | What it should contain | What to avoid |
|---|---|---|
| Site summary | One precise description of what the website does and who it serves | Generic positioning copy that could fit any company |
| Main pages | Homepage, service pages, product categories, documentation, contact paths | Every blog post, tag archive, redirected URL, or campaign page |
| Resources | Guides, FAQs, policies, technical references, public documents | Old PDFs with no HTML summary or outdated information |
| Language pages | Canonical localized URLs grouped by language or region | Mixed-language URLs, duplicate paths, or pages without proper localization |
| Sitemap reference | A link to the XML sitemap if useful | Treating llms.txt as a replacement for the XML sitemap |
A simple company website might structure the file like this in plain Markdown terms: site name, one blockquote-style summary, a "Company information" section, a "Products and services" section, a "Resources" section, a "Contact" section, and a "Sitemap" section. The descriptions should be specific. "Industrial valve category page with specifications and buyer guidance" is useful. "Learn more about our solutions" is not.
The most common wrong explanation is that llms.txt is "robots.txt for AI." That shortcut creates bad decisions. robots.txt is used for crawler access guidance and is formalized through the Robots Exclusion Protocol. llms.txt is a readable content guide. It does not block crawlers, grant permissions, remove pages from indexes, or prevent access to sensitive URLs.
How llms.txt differs from robots.txt, sitemap.xml, and schema markup
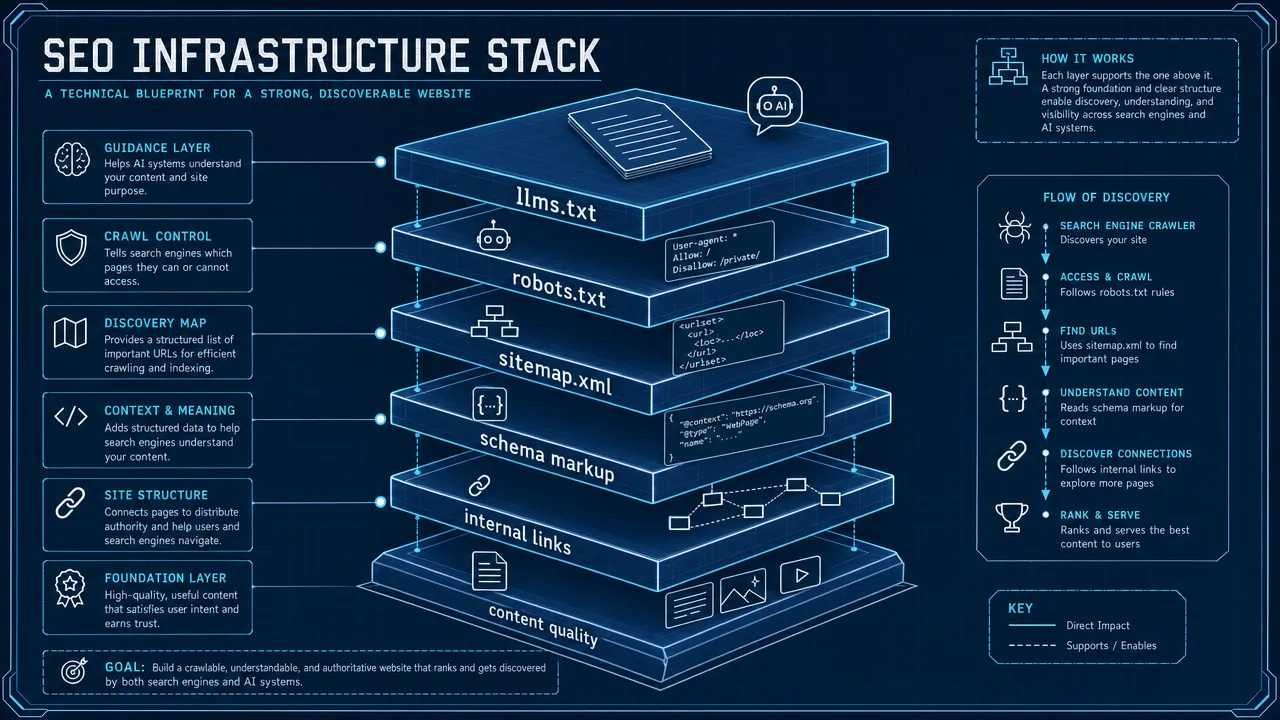
llms.txt belongs in the machine-readable website stack, but it plays a different role from established SEO infrastructure. A well-run website may use all four layers: robots.txt for crawler access guidance, sitemap.xml for canonical URL discovery, schema markup for page-level entity meaning, and llms.txt for curated site context.
The Google robots.txt documentation explains how robots.txt helps manage crawler access, while also warning that it is not a reliable way to remove a URL from search results if other pages link to it. The Sitemaps protocol defines XML sitemaps as a way to list URLs for discovery. The Google structured data introduction and Schema.org explain how structured data helps machines understand page-level entities and relationships.
Here is the practical distinction:
| Signal | Main job | Best used for | Common mistake |
|---|---|---|---|
robots.txt |
Crawler access guidance for compliant bots | Managing crawl paths and reducing crawler waste | Blocking important pages by mistake |
sitemap.xml |
URL discovery | Listing canonical, indexable URLs | Including redirects, noindex pages, duplicates, or parameter URLs |
| Schema markup | Entity and page meaning | Organization, Product, Service, Article, FAQ, Breadcrumb data | Adding markup that does not match visible page content |
llms.txt |
Curated site summary | Highlighting the most useful public pages for LLM systems and agents | Listing every URL or assuming guaranteed crawler support |
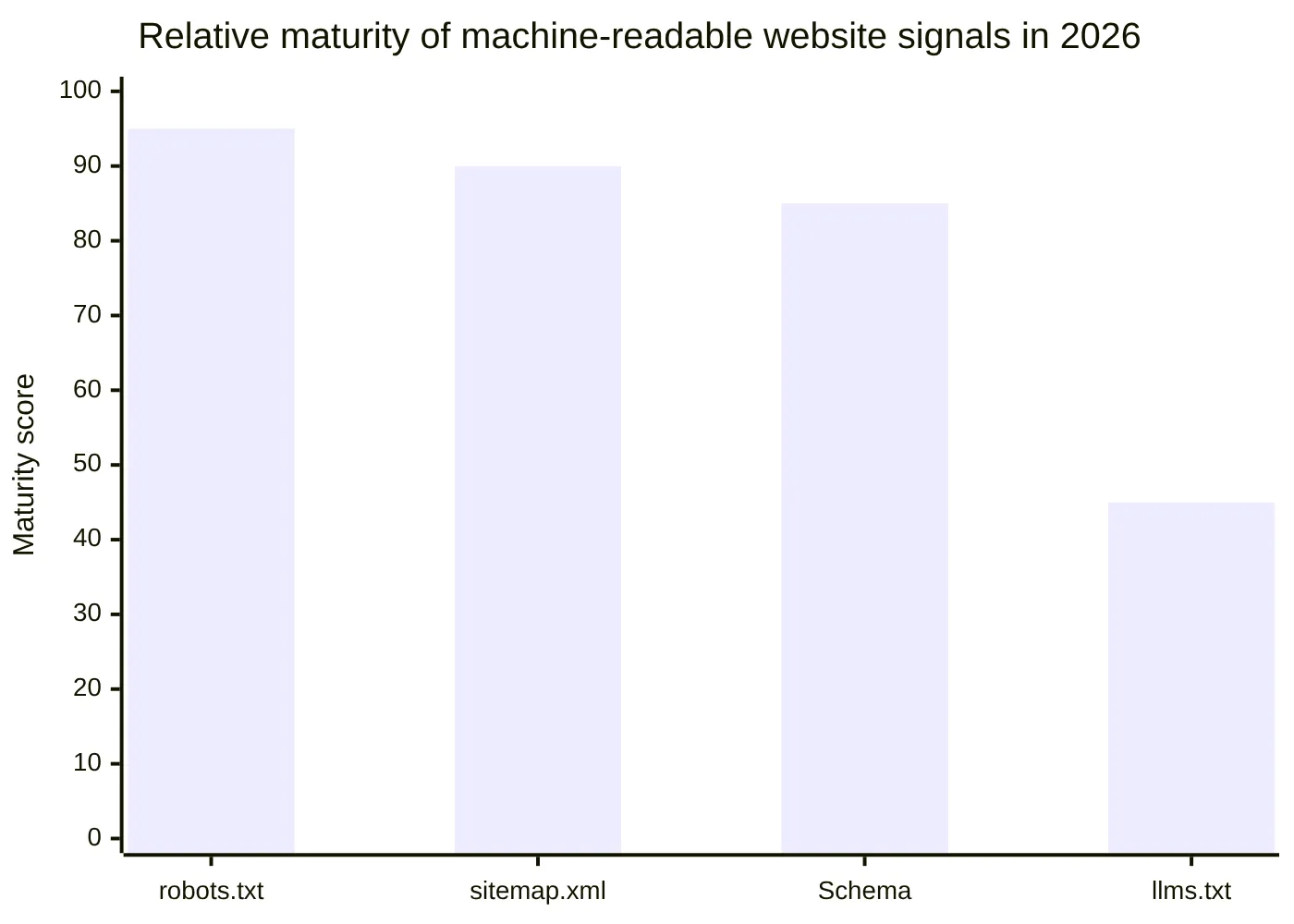
This chart is a qualitative maturity view, not a measured adoption dataset. It reflects the practical difference between long-established search infrastructure and the emerging status of llms.txt 2026 usage.
For a manufacturer, the split might look like this:
robots.txtprevents crawlers from wasting time on internal search results, cart paths, or filtered parameter pages.sitemap.xmllists canonical product category pages, service pages, resource hubs, and public articles.- Schema markup identifies the organization, breadcrumbs, product information, article metadata, and FAQs where accurate.
llms.txtsummarizes the company and links to the pages that best explain its products, technical capabilities, documentation, and inquiry routes.
That last point matters for independent websites and exporter websites. Many of these sites have scattered information: a product page says one thing, a PDF says another, a regional page is outdated, and the blog has no clear topical structure. A curated llms.txt file can expose that mess quickly. That is useful, but only if the team uses the exposure to clean the site rather than publish a neat file over weak foundations.
If schema gaps show up during this process, SeekLab.io's guide to entity SEO and schema roadmap is a useful next read because schema and llms.txt solve different machine-understanding problems. Schema describes what exists on a page. llms.txt explains which pages matter at the site level.
What llms.txt SEO value can and cannot prove
The safest statement about llms.txt SEO is this: the value is indirect and unconfirmed, but not meaningless. It can help a team decide which pages deserve to represent the brand, which URLs should be canonical, and whether the site has enough clear content for machine readers and real buyers to understand it.
No official Google documentation currently confirms llms.txt as a ranking factor. Public crawler documentation from major providers also continues to emphasize robots.txt and crawler-specific controls rather than llms.txt. OpenAI documents crawler controls through its bots documentation. Google documents crawler behavior and Google-Extended in its common crawlers documentation. Perplexity explains crawler controls in its crawler resources. Bing provides crawler information through Bing Webmaster Tools crawler documentation. These sources are useful because they show where official control language currently lives.
So what can llms.txt do?
| Possible value | Why it can help | What it does not guarantee |
|---|---|---|
| Better content curation | Forces teams to identify the strongest pages | Higher rankings |
| Clearer canonical focus | Reduces confusion around which URLs matter | Indexing by a specific LLM system |
| Better machine-readable summary | Gives LLM systems a concise guide to the site | AI-generated answer citations |
| Useful audit trigger | Exposes weak, stale, or duplicated content | Better conversion by itself |
| Future readiness | Low-effort layer if the site foundation is clean | Official crawler support |
The commercial implication is easy to miss. A business may improve traffic and still fail to generate inquiries if the pages in its llms.txt point to weak conversion paths. For example, an exporter can list 50 product URLs, but if those pages lack specifications, use cases, certifications, shipping context, and a visible request path, the file simply routes attention toward poor buyer information.
This is where LLM website indexing and real SEO work overlap. A page must first be worth understanding. It should be crawlable, indexable, internally linked, specific to buyer intent, and supported by clear page structure. For multilingual websites, it should also align with canonical and hreflang logic. Google's international SEO documentation remains more important than any informal language-section pattern in an llms.txt file.
A useful warning: do not sell or buy llms.txt implementation as a shortcut. If a site has noindex product pages, a bloated sitemap, broken schema, slow templates, or important copy rendered only after JavaScript execution, llms.txt is not the fix. SeekLab.io's article on JavaScript SEO indexing solutions covers one of the more common technical traps: the page looks complete to users, but crawlers may not see the same meaningful content.
How to create an llms.txt file without weakening site quality
A good llms.txt implementation starts with page selection, not file generation. Developers can publish the file in minutes. The harder part is deciding which URLs deserve to be highlighted.
Start with canonical high-value pages. These are usually the homepage, primary service or product category pages, resource hubs, FAQs, case studies if current and public, documentation, certification pages, contact pages, and the XML sitemap. For a content-heavy blog, include pillar guides and category hubs rather than every post. For a B2B catalog site, include major category pages and technical documentation before individual SKUs unless specific product pages are genuinely important.
Every URL in the file should pass a basic technical check:
| Check | Pass condition | Why it matters |
|---|---|---|
| HTTP status | Returns 200 | Avoids sending systems to broken or redirected pages |
| Canonical | Self-canonical or correctly canonicalized | Reduces duplicate URL confusion |
| Indexability | Not noindex if intended for discovery | Prevents highlighting pages that search systems should ignore |
| Robots access | Not blocked if public discovery is intended | Keeps access rules aligned with guidance |
| Internal links | Reachable from the site structure | Confirms the page is not orphaned |
| Content quality | Clear, current, and useful | Prevents weak pages from becoming the site's "recommended" sources |
| Language alignment | Correct language path and hreflang relationship | Avoids multilingual confusion |
Then write short descriptions tied to page purpose. A useful description names the role of the page. For example: "Technical guide for comparing stainless steel component grades by use case" is better than "Helpful guide." For a service page, "SEO audit service covering crawlability, indexation, schema, internal links, performance, and rendering checks" is better than "Our services."
For multilingual sites, group URLs by language or region. Do not mix /en/, /de/, and /zh/ URLs inside one vague section unless the relationship is obvious. If a business has separate country sites or subdomains, each host may need its own file, but that is an implementation pattern, not a confirmed crawler requirement. Clean hreflang, localized content quality, and canonical structure come first. SeekLab.io's multilingual SEO strategy explains the architecture decisions that should happen before a language-aware llms.txt file is published.
A practical structure can include:
- Site name.
- One concise summary of the company or website.
- Core services or product categories.
- Documentation, resources, or knowledge base.
- Blog hubs or pillar content.
- Contact, inquiry, quote, or demo pages.
- Language and region versions.
- XML sitemap reference.
- Freshness note, such as quarterly review.
Use this as a plain-text pattern, not a code block:
# Example Company> Example Company provides industrial components and technical resources for procurement and engineering teams.## Company information- [About Example Company](https://www.example.com/about/): Company background, capabilities, and markets served.## Products- [Industrial Components](https://www.example.com/products/industrial-components/): Main product category with specifications and buyer guidance.## Resources- [Technical Resources](https://www.example.com/resources/): Guides, specifications, and reference material.## Contact- [Request a Quote](https://www.example.com/request-a-quote/): Inquiry path for product and project requests.
After publishing, validate the file. Confirm /llms.txt returns HTTP 200, renders as readable text, uses clean Markdown, and contains no broken links. Crawl every listed URL. Compare the list against the XML sitemap. Add the file to the quarterly SEO maintenance checklist and review it after redesigns, migrations, product launches, market expansion, or content pruning.
The most damaging mistakes are usually simple:
| Mistake | Why it hurts |
|---|---|
| Listing every sitemap URL | Turns a curated guide into a noisy URL dump |
| Including noindex pages | Sends conflicting signals about what should be discovered |
| Linking to redirected URLs | Adds unnecessary ambiguity |
| Adding vague descriptions | Gives machine readers no useful context |
| Forgetting localized pages | Weakens multilingual clarity |
| Highlighting stale PDFs | May surface outdated product or compliance information |
| Ignoring JavaScript rendering | The page may not expose the same content to crawlers |
| Treating it as a one-time task | The file becomes stale after site changes |
How llms.txt fits the Two-Gate Model for AI citations
SeekLab.io's Two-Gate Model describes two separate requirements for AI citations: Gate 1 is retrieval — can an AI system find and access your content — and Gate 2 is absorption — does the retrieved content contain specific, extractable claims worth citing.
llms.txt is purely a Gate 1 tool. At best, it can make retrieval faster and cleaner for AI agents that choose to read it. It does nothing for Gate 2. A site with a perfectly curated llms.txt file but vague, generic page content will still fail to produce AI citations. The file organizes the front door. It does not improve what is inside the rooms.
This is the most common misunderstanding about llms.txt SEO. Teams that treat the file as a substitute for Gate 2 work — direct verdict sentences, specific numbers, "Best for:" labels — are solving the easier problem while leaving the harder one untouched.
When SeekLab.io recommends prioritizing llms.txt
SeekLab.io treats llms.txt as a useful readiness layer, not a first-priority fix. For most independent websites, official company sites, exporter websites, and multilingual brand sites, the right sequence is: fix discoverability and page quality first, then publish a curated llms.txt file.
The work before llms.txt usually has higher growth impact:
| Priority | What to check first | Business reason |
|---|---|---|
| 1 | Indexability and crawlability | Important pages must be accessible before they can support traffic or inquiries |
| 2 | robots.txt and sitemap.xml |
Search engines need clean crawl and discovery signals |
| 3 | Site architecture and internal links | Buyers and crawlers both need a clear path to important pages |
| 4 | Content depth and conversion pages | Rankings are less useful if pages do not answer buyer questions or support inquiries |
| 5 | Schema markup | Entity clarity helps machines understand page meaning |
| 6 | Core Web Vitals and rendering | Slow or poorly rendered pages limit discovery and user experience |
| 7 | Multilingual structure | International pages need consistent language, canonical, and hreflang signals |
| 8 | llms.txt |
Curated guidance becomes useful once the highlighted pages are worth recommending |
SeekLab.io's SEO audit checklist for 2026 is a good starting point if the site has not been technically reviewed. It covers the kind of foundational checks that decide whether llms.txt should be done now or later: crawling, indexation, performance, internal links, schema, JavaScript compatibility, and international setup.
For content selection, llms.txt also exposes a strategic issue: many websites do not know which pages matter most. A company may have 200 articles, but only 12 explain buyer pain points, product differences, regulations, implementation details, or pricing logic well enough to support qualified leads. SeekLab.io's SEO topic and keyword research focuses on choosing topics and pages based on intent and business scenarios, not just search volume.
SeekLab.io helps brands build search visibility and AI-era discoverability through high-quality content production and technical optimization. The work is not limited to technical issue detection. It includes content structure, information clarity, page architecture, internal linking, schema readiness, multilingual site architecture, and practical decisions about what to fix now versus what can wait. That distinction matters because many teams waste budget on visible tasks while ignoring the problems that actually block growth.
A realistic recommendation:
| Site condition | Should you add llms.txt now? |
Better next step |
|---|---|---|
| Clean sitemap, strong pages, good schema, clear internal links | Yes, it is a reasonable low-effort addition | Create and maintain a curated file |
| Broken sitemap, many noindex or redirected URLs | Not yet | Fix discovery and indexability first |
| Thin product or service pages | Not yet | Improve content depth and buyer usefulness |
| Multilingual URLs are inconsistent | Wait | Clean language paths, canonicals, and hreflang |
| Documentation-heavy site with strong content | Yes | Highlight docs, guides, and canonical resources |
| Recent redesign or migration | Only after validation | Crawl the site and confirm URLs before publishing |
If you are unsure whether your site is ready for llms.txt, start with a free audit report. SeekLab.io can check crawlability, sitemap accuracy, robots.txt rules, schema, internal links, JavaScript rendering, multilingual structure, and whether the pages you plan to highlight are strong enough to support SEO and conversion. You can also contact SeekLab.io if you need help deciding what to fix first.
Quick answers about llms.txt
| Question | Honest answer |
|---|---|
What is llms.txt? |
A proposed Markdown file at /llms.txt that summarizes a site and links to important resources for LLM systems. |
Is llms.txt official in 2026? |
It is an emerging proposal and community practice, not a formal web standard. |
Does llms.txt improve Google rankings? |
No verified public evidence confirms it as a direct Google ranking factor. |
Is llms.txt the same as robots.txt? |
No. robots.txt is for crawler access guidance; llms.txt is a curated content guide. |
| Should every page be included? | No. Include only canonical, public, current, high-value pages. |
| Can it help AI crawler guidance? | It can provide guidance, but it does not control permission, blocking, or indexing. |
| How often should it be updated? | Quarterly for most company websites, and after redesigns, migrations, product changes, or multilingual expansion. |
| What should come before it? | Crawlability, indexability, sitemap accuracy, robots.txt validation, internal links, schema, content depth, rendering, and multilingual structure. |
llms.txt is worth adding when it reflects a website that is already clear, crawlable, and commercially useful. If the underlying site is weak, the file does not solve the problem. It simply makes the weakness easier to find.


